
博客
低精度浮点数定义——什么是 FP8、FP6、FP4?

浮点精度是一种以二进制格式表示数字的方法,计算机将数字解读为由 0 和 1 组成的二进制序列。我们在之前的博客中已探讨过半精度(FP16)、单精度(FP32)和双精度(FP64)浮点数,本文将聚焦于更小众的低精度格式——FP8、FP6和FP4,这类格式更适用于神经网络与人工智能领域。
在浮点数表示中,第一个二进制位表示数字的正负(符号位);接下来的一组二进制位构成指数位,以 2 为基数表示数字的量级;最后一组二进制位为尾数位(也称为有效数字位),表示数字的小数部分。在这些低精度格式中,核心目标并非保持数学精度,而是尽可能节省计算资源、内存空间和带宽,从而提升人工智能任务的响应速度与整体性能。
首先需要说明,浮点数精度降低的核心原因并非数学限制,而是数据移动的瓶颈。
将权重和激活值在内存中传输所消耗的时间与能量,远高于对它们进行乘法运算的成本。随着模型规模不断扩大(尤其是大语言模型),性能瓶颈逐渐转向内存带宽、缓存容量和功耗,而非浮点运算吞吐量。降低数值精度是缓解这些瓶颈最有效的手段之一。
这也是行业从 FP32 转向 FP16 和 BF16 的原因——且即便如此,精度降低的需求仍未得到满足。
降低精度可实现以下优势:
-
缩小模型体积,提升缓存局部性
-
提高有效内存带宽
-
降低单次运算的能耗
-
提升计算资源利用率
人工智能神经网络训练本身具有一定的近似容错性:训练过程中会刻意引入噪声,采用随机优化方法,且评估的是整体表现而非精确的数值正确性。因此,精度不再是固定要求,而是需要谨慎分配的“资源预算”。
问题的核心也从“应使用何种精度?”转变为“精度在哪些环节至关重要?”
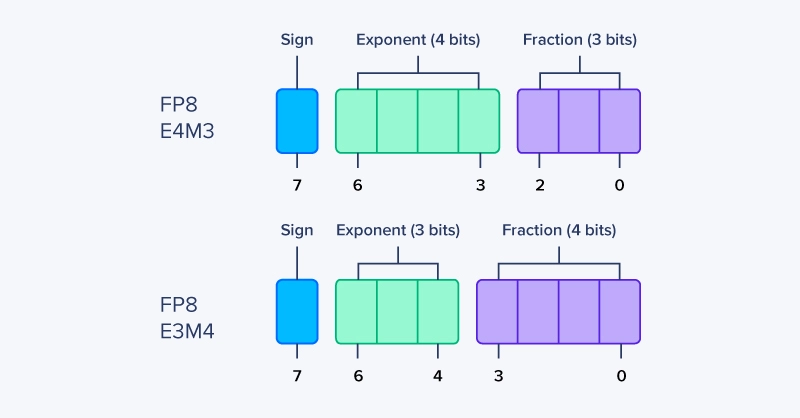
FP8 指的是一类 8 位浮点数格式,而非单一标准。与更大的 IEEE 浮点数类型类似,FP8 包含两种版本:E4M3 和 E5M2(命名直观反映其位分配规则)。
对于 8 位长度的浮点数,单一格式无法同时兼顾足够的数值范围和精度。因此,现代硬件与框架会混合使用两种 FP8 变体:
-
FP8 E4M3 适用于数值精度更关键的场景
-
FP8 E5M2 适用于动态范围成为限制因素的场景
在实际应用中,FP8 极少单独使用:计算过程通常以 FP8 执行,而累加运算则在 FP16 或 FP32 精度下进行。这种方式在大幅降低存储和计算精度的同时,保障了训练与推理的稳定性。
FP8 被广泛应用于多款人工智能加速器,核心原因在于其能够完美适配混合精度工作负载。
什么是 FP8 E4M3?
FP8 E4M3 优先保证精度而非范围。更多的尾数位使其能更精确地表示接近零的数值,因此非常适合分布相对集中的激活值和梯度。其位分配如下:
-
1 位:表示正负的符号位
-
4 位:以 2 为基数的指数位
-
3 位:尾数位/有效数字位/小数位(即小数点后的数值部分)
什么是 FP8 E5M2?
FP8 E5M2 将部分尾数位分配给指数位,以牺牲精度为代价扩大了可表示的数值范围。这使其对异常值和大动态范围具有更强的鲁棒性,适用于权重和中间结果等场景。其位分配如下:
-
1 位:表示正负的符号位
-
5 位:以 2 为基数的指数位
-
2位:尾数位/有效数字位/小数位(即小数点后的数值部分)
FP6 并非单一的标准化格式,而是一类 6 位浮点数表示方法。与 FP8 类似,FP6 也由符号位、指数位和尾数位组成——但由于仅含 6 位,其优势与取舍更为极端。
尽管具体实现存在差异,但大多数 FP6 方案遵循以下通用模式:
FP6 E2M3
-
1 位:表示正负的符号位
-
2 位:以 2 为基数的指数位
-
3 位:尾数位/有效数字位/小数位(即小数点后的数值部分)
FP6 E3M2
-
1 位:表示正负的符号位
-
3 位:以 2 为基数的指数位
-
2 位:尾数位/有效数字位/小数位(即小数点后的数值部分)
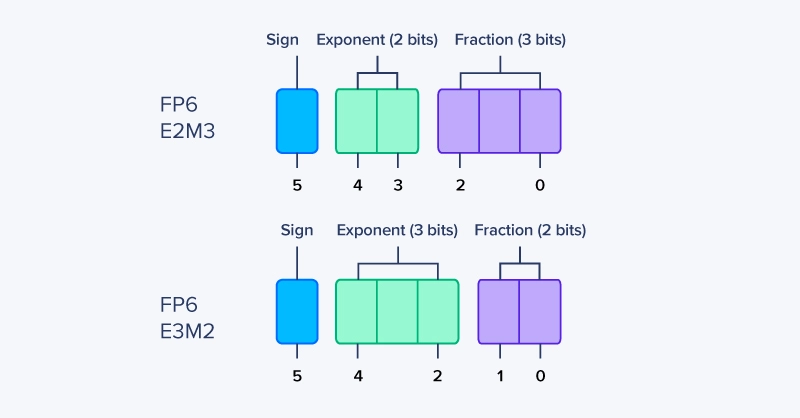
FP6 相关:E2M3 与 E3M2 详解
不同的指数位-尾数位分配比例适用于不同场景,但所有 FP6 格式都存在数值范围或精度极度受限的问题——通常两者同时受限。与 FP8 不同,单一 FP6 格式几乎没有平衡范围与精度的空间。因此,使用 FP6 几乎必然需要采用激进的数值缩放策略和严格的数值分布控制。
相较于 FP8,FP6 带来的效率提升有限,但复杂度成本却显著增加。在多数情况下,FP8 已能捕获大部分性能和内存优势,同时不会将数值稳定性推向崩溃边缘。
FP6 仅在以下条件下具有可行性:
-
数值分布狭窄且规律
-
按层或按张量实施数值缩放
-
累加运算在 FP16 或 FP32 精度下进行
FP4 是当前实际讨论中精度最低的浮点数格式。仅 4 位的长度将浮点数的性能推向绝对极限,其存在的核心目的几乎完全是为了满足硬件吞吐量和密度目标。截至目前,仅有 NVIDIA Blackwell 系列 GPU 原生支持 FP4 精度。
FP4 没有统一标准,但典型设计的位分配如下:
-
符号位:1 位
-
指数位:2 位
-
尾数位:1 位
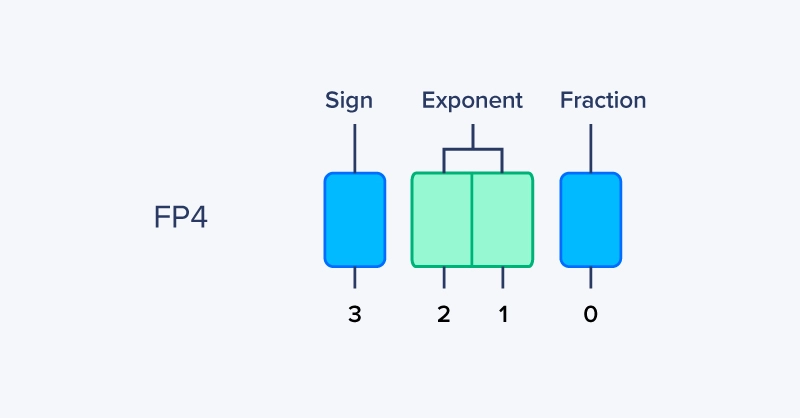
FP4 相关详解
部分变体通过调整指数偏置或完全移除特殊值来优化性能。无论具体布局如何,FP4 的数值范围都极度有限,且几乎没有精度可言。FP4 的核心作用是通过实现极高的计算密度,最大化张量核心吞吐量并最小化内存带宽消耗。
从数值角度看,FP4 并非为单独使用而设计:它是一种计算格式,而非存储或累加格式。当硬件规格中提及FP4 时,通常遵循以下逻辑:
-
数值通常经过缩放或块缩放处理
-
计算过程以 FP4 执行
-
累加运算在 FP16 或 FP32 精度下进行
-
输入和输出通常以更高精度存储
这一逻辑契合行业大趋势:计算环节采用越来越低的精度,而在误差易累积的环节保留更高精度。
因此,FP4 更应被视为一种硬件能力,而非通用的数值格式。其被纳入 NVIDIA GPU 规格,反映的是 GPU 的性能极限方向,而非当前多数模型的可运行精度。计算过程中位长度的减少,降低了运算复杂度并加快了执行速度——在 GPU 执行人工智能训练与推理过程中万亿次的运算中,这种优势会不断累积放大。
现代人工智能系统并非采用单一精度运行,而是刻意在存储、计算和累加等环节混合使用不同精度,仅在数值误差易累积的关键环节保留较高精度。
这也是极低精度格式能够可行的核心原因:
-
计算环节使用 FP8、FP6 甚至 FP4,以最大化吞吐量
-
存储环节优先选择能保证精度的最小格式
-
累加环节保留 FP16 或 FP32 精度,以维持数值稳定性
一种精度格式的有效性,与其位数关系较小,更取决于其在整个计算流程中的应用场景。
-
FP8:最佳通用低精度浮点数,适用于训练和推理计算,搭配高精度累加
-
FP6:实验性与专用性格式,仅在严格缩放和受控分布条件下可行
-
FP4:硬件驱动的极限精度格式,仅在严格约束下作为计算格式使用,不可单独应用
低精度并非意味着在所有环节牺牲正确性,而是在关键环节合理分配精度资源,在其他环节回收效率收益。
1. 为何降低精度不会彻底破坏模型精度?
神经网络本身具有噪声容错性。只要累加和缩放处理得当,低精度计算引入的微小数值误差不会显著影响最终输出结果。
2. 为何选择 FP8、FP6 等浮点数格式而非整数格式(如 INT8)?
浮点数格式能够保留动态范围,这对激活值和梯度至关重要。整数格式需要显式校准,且难以应对快速变化的数值分布。
3. 为何累加运算几乎总是采用更高精度?
误差会在累加过程中不断累积。即使输入是极低精度,使用 FP16 或 FP32 进行累加也能避免微小的舍入误差主导最终结果。
4. 为何 FP4 已有硬件支持却未被广泛使用?
FP4 的数值范围和精度极度有限。若缺乏严格的缩放和受控的数值分布,数值误差会迅速扩大,超出多数模型的容忍范围。
5. 如何在 FP8、FP6 和 FP4 之间选择?
多数低精度计算场景优先选择 FP8;FP6 仅适用于专用或实验性场景;将 FP4 视为硬件优化手段,而非通用数值格式。
低精度浮点数格式在吞吐量、延迟或功耗为核心约束的场景中极具优势,具体应用包括:
-
大语言模型(LLM):FP8 越来越多地用于训练和推理计算,而 FP4 则在严格控制的推理内核中使用,以最大化张量核心利用率
-
数据中心推理:FP8 和 INT8 降低了每 Token 的内存带宽消耗和能耗,直接提升成本效益和可扩展性
-
机器人与自动驾驶系统:在严格的功耗和散热限制下,低精度计算可提升控制环路速率,尤其适用于边缘加速器
-
推荐与排序模型:这类模型对近似计算容忍度高,通过激进的精度降低可满足延迟目标
-
含学习组件的科学与工业仿真:替代模型和学习求解器通常能在 FP8 精度下高效运行,且性能无明显下降
这些场景的共性并非应用领域,而是核心约束:当数据移动成本高于计算成本时,低精度格式能带来显著收益。
随着硬件与软件的协同演进,未来数值格式的发展方向将更少依赖 IEEE 标准,更多取决于精度资源的高效分配能力。




相关贴子
-
 HPC
HPC用绿色算力重新定义边疆的巍峨硅谷
2025.06.06 15分钟阅读 -
 HPC
HPC数据中心中的 InfiniBand 与以太网
2025.07.11 32分钟阅读 -
 HPC
HPC英特尔 Ponte Vecchio 和 Xe HPC 架构:专为大数据打造
2022.07.14 0分钟阅读