
博客
基于 LoRA 技术的人工智能模型微调

高性能硬件的获取并非总能实现。你可能不具备对深度求索 R1(DeepSeek R1)或 llama 3 这类基础大语言模型开展全量微调的硬件条件;或者你的企业已在核心计算架构上完成了模型训练,但启动微调流程会中断其他新项目的推进。
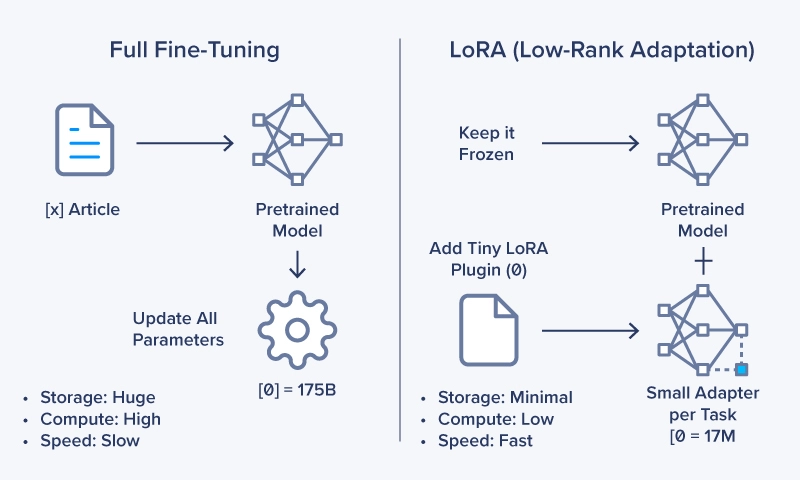
低秩适配技术(LoRA)是一种高效的大语言模型微调方法,无需对模型的全部参数进行重新训练。借助该技术,即便是配备联泰集群 GPU 工作站或联泰集群 GPU 服务器这类中端硬件的团队,也能开展模型定制工作,无需依赖大规模计算集群或高端显卡。
本指南将阐释 LoRA 的工作原理、技术实用性,以及它在实际人工智能开发场景中的应用方式 —— 尤其是与为高效训练流程量身打造的硬件搭配使用时的协同效果。
低秩适配技术(LoRA)通过仅更新模型中的少量参数,而非对整个模型进行重训,实现大语言模型的高效微调。
这一技术让不具备全规模计算架构的团队,也能针对特定业务场景对基础模型进行定制化开发。技术人员、企业或业务部门无需投入大规模计算资源,即可完成基础模型的微调工作。
LoRA 的核心工作机制是冻结原始模型的权重参数,仅对新增的少量低秩矩阵展开训练。这种方式既能保留基础模型的原有性能,又能使其适配新的数据或任务需求。
-
可将待训练参数的规模压缩至全量模型的 1%–2% 左右。 -
由于训练过程中模型的大部分参数保持固定,对显卡显存的需求大幅降低。 -
仅需优化轻量级的低秩矩阵组件,大幅缩短微调周期。
举个对比案例:对一个拥有 1000 亿参数的模型进行全量微调时,LoRA 技术可能仅需更新数百万个参数。这种方式能在不降低输出质量的前提下,实现更快速、更高效的模型训练。
对于需要为特定场景定制模型,但又希望规避传统微调高昂成本的团队而言,LoRA 技术能直接创造价值。它所具备的实用优势,是提示词工程或全量微调技术难以企及的。
-
降低计算资源需求:基础模型的大部分参数处于冻结状态,因此显存占用量显著下降,仅为传统全量微调的 1/8 甚至 1/16。团队无需搭建昂贵的计算集群,也不必占用核心计算架构,即可完成大模型的微调工作。 -
缩短微调周期:待计算的参数数量大幅减少,训练任务的完成速度显著提升。这使得团队能在相同时间内开展更多实验迭代,更频繁地完成模型更新。 -
简化模型定制流程:可针对不同任务打造多个轻量化、易存储的 LoRA 适配器,例如面向特定领域的智能助手、经过优化的客服对话机器人等。 -
降低总拥有成本:训练参数减少意味着显卡运行时长和电力消耗降低,小型化的训练任务能有效压缩运营成本,让预算规划更具可预测性。同时,较低的计算需求可避免团队过度采购硬件设备。 -
实现可扩展、易维护的工作流:LoRA 适配器采用模块化设计,便于进行版本管理。团队无需重新训练基础模型,即可维护多个面向不同任务的适配器;每个适配器仅对应单一任务或数据集,让整体工作流更简洁清晰。
微调所需的显卡显存需求
以下表格以 70 亿参数(7B)的模型为基准,提供了使用 LoRA 和 QLoRA 技术微调大语言模型(LLM)时的显存需求估算数据:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
影响显卡需求的关键因素
-
模型规模:这是首要影响因素,模型参数规模越大,对显存的需求自然越高。 -
数据精度:采用低精度格式(BF16/FP16 或 INT8/FP8)可将模型权重的显存占用量减少一半。QLoRA 技术进一步将基础模型量化至 4 比特(INT4),虽会牺牲一定精度,但能大幅降低显存消耗,不过这种精度损失对模型性能的影响存在不确定性。 -
优化器选择:AdamW 是常用的优化器,但它会存储额外的状态信息,增加显存占用。若改用随机梯度下降(SGD)这类更简单的优化器,可小幅节省显存空间。 -
梯度检查点技术:这是一种优化手段,通过在反向传播过程中重新计算部分激活值,而非存储这些数据,来降低显存占用,但会略微延长训练时间。 -
批次大小与序列长度:更大的批次大小和更长的序列长度(即提示词上下文长度),会同时增加显存消耗和计算耗时。
实用显卡选型建议
-
70 亿参数及以下模型(搭配 QLoRA 技术):显存容量为 8GB 或 12GB 的显卡可满足基本需求,但需设置极小的批次大小,训练时长会相应增加。无论是 LoRA 还是 QLoRA 技术,更大的显存容量都能为实验提供更高的灵活性。 -
320 亿–700 亿参数模型:配备多显卡的联泰集群 GPU 工作站可提供充足显存。例如,搭载 2 块 NVIDIA RTX PRO 6000 Blackwell 显卡(单卡显存 96GB,总计 192GB)的工作站,可高效加载并完成对 700 亿参数模型的 LoRA 微调。 -
700 亿参数以上大模型:通常需要部署专业级多显卡系统。新一代显卡在这类场景中优势显著:配备 4 块 NVIDIA RTX PRO 6000 Blackwell 显卡的联泰集群 GPU 工作站或服务器,可提供 384GB 的总显存,支持对 1400 亿参数模型的训练;更大规模的模型则可通过单台 4U 节点扩展至 8 块显卡的配置。
借助 LoRA 和 QLoRA 这类技术,过去需要依赖昂贵多显卡数据中心架构才能完成的大模型微调任务,如今在经济实惠的单显卡、多显卡或单节点硬件配置上也能实现。
什么是 LoRA?它为何具有重要意义?
LoRA(低秩适配技术)通过仅更新大语言模型中的一小部分参数实现微调,大幅降低计算资源需求、显存占用和训练时间。该技术让企业无需投入超大规模硬件或承担巨额基础设施成本,即可开展模型定制工作。
LoRA 如何降低微调成本?
传统全量微调需要更新数十亿参数,需消耗大量显存并产生高昂成本。LoRA 技术冻结原始模型权重,仅训练小型低秩矩阵,所需显存和显卡运行时长大幅减少,直接降低了技术的总拥有成本。
LoRA 如何优化企业级人工智能工作流?
LoRA 支持为不同任务创建轻量化适配器,无需重新训练基础模型即可切换适配器,实现更快速的迭代开发、可版本化的部署流程,同时最大限度降低推理阶段的性能开销。
LoRA 是否兼容我现有的显卡设备?
是的。LoRA 技术不仅适用于尖端计算集群,在中端显卡和工作站级显卡上也能高效运行。联泰集群的人工智能工作站和服务器针对 LoRA 工作负载进行了深度优化,实现了显存容量、计算密度与散热稳定性的平衡。
为什么选择 LoRA 而非全量微调或提示词工程?
提示词工程实施便捷,但功能存在明显局限性;全量微调效果强劲,但成本高昂。LoRA 技术以远低于全量微调的计算成本,实现接近全量微调的模型性能,同时生成可复用的轻量化适配器,是追求高性价比定制化人工智能方案的企业的理想选择。
LoRA 技术为大语言模型微调提供了一种实用方案,摆脱了传统微调方法对高性能计算资源的依赖。它降低了训练成本,缩短了迭代周期,让团队能够在硬件需求可预测的前提下,构建面向特定领域的人工智能应用。
当 LoRA 技术与联泰集群硬件搭配使用时,其易用性将进一步提升。无论是在工作站上对 70 亿参数模型进行微调,还是在多显卡服务器上处理更大规模的工作负载,联泰集群的硬件产品都能提供高效运行 LoRA 所需的显卡性能、系统稳定性和配置灵活性。
对于希望以合理成本实现人工智能定制化的企业而言,LoRA 技术提供了一条切实可行的路径。依托合适的硬件基础,企业能够更快完成模型开发、更智能地进行部署,并信心十足地推动人工智能项目的规模化落地。





相关贴子
-
 技术分享
技术分享【技术大讲堂】ShengBTE 的安装与使用
2024.09.20 32分钟阅读 -
 技术分享
技术分享AlphaFold 更新显著提高了对接、核酸和 PTMS 的准确性
2024.04.12 14分钟阅读 -
 技术分享
技术分享Docker 容器在软件部署中的重要性
2025.06.13 29分钟阅读