
博客
Pacefish CFD 中 RTX PRO 6000 Blackwell 系列与 RTX 6000 Ada GPU 的基准测试

计算流体动力学(CFD)要求从业者和工程师能够快速准确地做出最明智的设计决策。随着模型变得越来越复杂,处理和收集结果所需的时间也越来越长。
Numeric Systems 的 Pacefish® 是一个 CFD 模拟软件套件,优先考虑短周转时间,具有高 GPU 加速和可扩展性的可靠结果。
GPU 加速计算已经达到了一个点,在大多数并行工作负载中,它的性能已经得到了优化,远远高于 CPU。对于工程师和研究人员来说,这意味着他们可以更快地迭代并模拟更大的模拟。
从航空航天到汽车再到土木工程,各行各业都可以从将 GPU 加速计算纳入其计算基础设施中受益,从而缩短上市时间,同时提高产品质量。模拟更大、更详细模型的能力也为创新打开了大门。
-
时间:完成时间更短意味着可以在生产前运行更多的模拟测试进行微调。更短的等待时间意味着更快地获得结果并加速工作流程。
-
复杂性:即使在高度复杂的模型上,速度的提高也能更好地表示模拟。虽然 GPU VRAM 与 CPU RAM 相比是有限的,但新的 GPU 版本增加了 VRAM 容量,非常适合可视化、仿真和其他 HPC 工作负载。经过测试的 NVIDIA RTX PRO 6000 Blackwell 具有 96GB 的 VRAM!
-
成本:单个 GPU 的性能相当于数百个 CPU 内核。部署数百个 CPU 核心需要一组计算服务器,更不用说运行和维护的总成本了。但是,可以在工程师的办公桌上配置和部署单 GPU 或多 GPU 工作站。
在这里,我们测试了三款顶级的 NVIDIA RTX GPU。NVIDIA RTX PRO Blackwell 系列与 NVIDIA RTX Ada Lovelace 系列的主要区别和优势是:
新的 NVIDIA Blackwell GPU 架构,增加了 CUDA 内核和原始 FP32 性能
具有更高内存带宽的新型 GDDR7
将 VRAM 从之前的 48GB 增加到现在的 96GB
转向 PCIe 5.0 以获得更高的带宽和数据传输速率
我们还测试了 600W 的 NVIDIA RTX PRO 6000 Blackwell 和 300W 的 NVIDIA RTX PRO 6000 Blackwell Max-Q 工作站版 GPU,以确定额外的功耗是否带来了可观的性能提升。
| NVIDIA RTX 6000 | NVIDIA RTX Pro 6000 Blackwell
Max-Q(300W) |
NVIDIA RTX Pro 6000 Blackwell
工作站(600W) |
|
| MVP 的平均性能
(每秒百万卷) |
777.78 | 1070.11 | 1129.33 |
| 相对加速
(VS NVIDIA RTX 6000) |
1.0 倍 | 1.38 倍 | 1.45 倍 |
NVIDIA RTX 6000 Ada 的相对加速
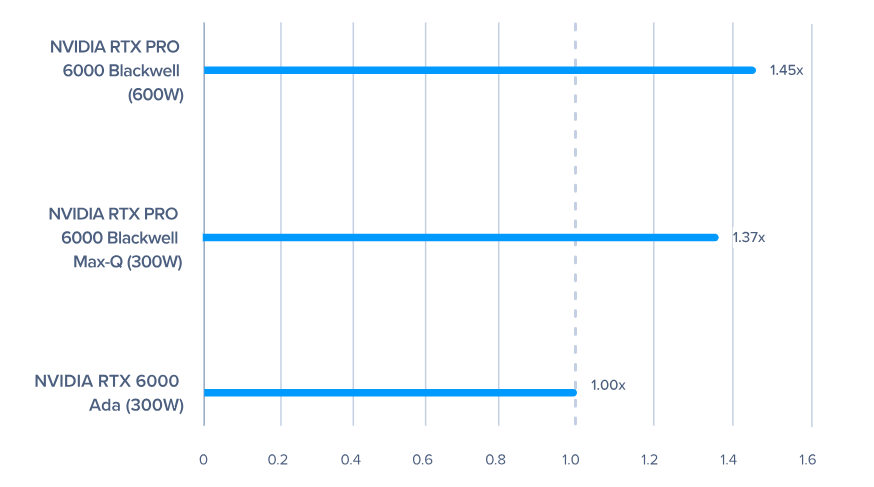
在 Pacefish CFD 工作负载中,与 NVIDIA RTX 6000 Ada 相比,NVIDIA RTX PRO 6000 Blackwell Series 在 600W 版本上的加速是 1.45 倍,在 300W Max-Q 版本上的速度是 1.38 倍。这在预期的范围内,反映了单精度 FP32 的性能改进:NVIDIA RTX 6000 Ada 的 91.1 TFLOPS 到 NVIDIA RTX PRO 6000 Blackwell 的 125 TFLOPS(125 TFLOPS÷91.1 TFLOLPS=1.37 倍性能增益)。
Pacefish 没有显示出更高内存带宽的任何重大影响。此外,与 300W Max-Q Edition 相比,使用 NVIDIA RTX PRO 6000 Blackwell 工作站版 600W 时性能提升最小,表现出类似的性能。
Blackwell VS Ada 在 Pacefish 中 MVPS 的表现(越高越好)
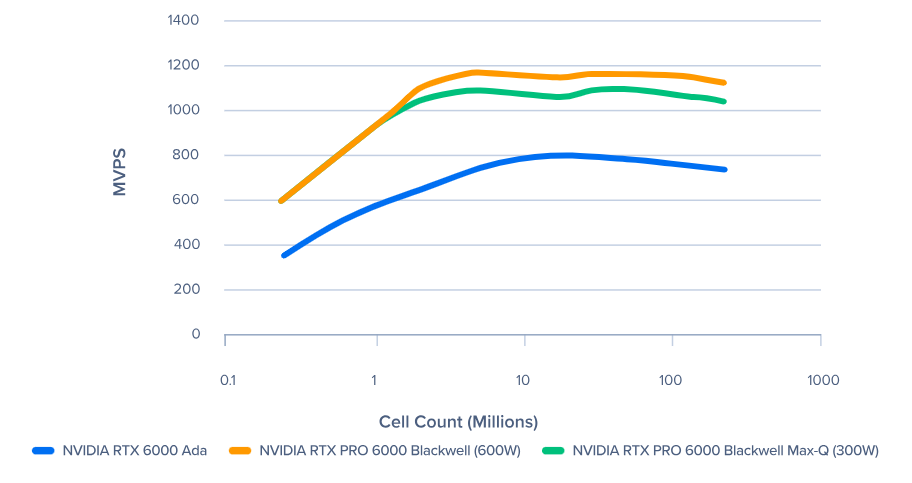
当使用小到大的单元数量运行问题尺寸时,我们看到 NVIDIA RTX PRO Blackwell 系列可以更快地提供峰值性能。我们将此归因于更快的 PCIe 5.0 通道速度(与 PCIe 4.0 相比)和更高的内存带宽,这可以更快地使 GPU 充满数据。当使用多个 NVIDIA RTX PRO 6000 Blackwell 系列 GPU 时,这也可以提高扩展性能。下图显示了这种快速饱和:
Blackwell VS Ada 在 Pacefish 中性能效率方面的比较(越高越好)
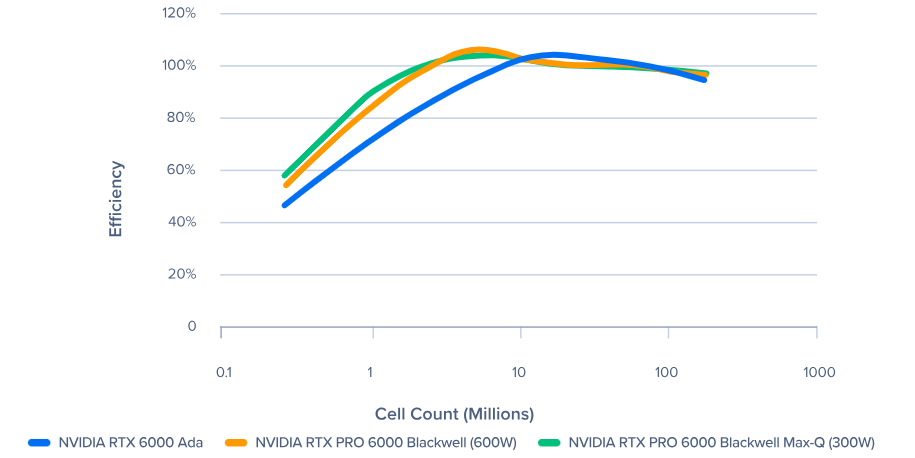
现在,最具影响力的改进是,NVIDIA RTX PRO 6000 Blackwell 具有 96GB 的 VRAM,是 NVIDIA RTX 6000 Ada 的 48GB 的两倍。凭借强大的可扩展性,工程师可以加速极其庞大和复杂的模型。借助 NVIDIA RTX PRO 6000 Blackwell 系列,工程师现在可以模拟比 NVIDIA RTX 6000 Ada GPU 多一倍的单元数量。
-
性能提升:与 Ada GPU 相比,NVIDIA Blackwell GPU 在运行 Pacefish 模拟时的速度分别提高了 1.45 倍(600W)和 1.38 倍(300W)。
-
电源效率:有趣的是,300W NVIDIA Blackwell 版本的性能几乎与 600W 版本一样好,这表明 Pacefish 工作负载的功耗回报率在下降。这对于使用 NVIDIA RTX PRO 6000 Blackwell Max-Q(300W)的多 GPU 部署来说是个好消息。
-
内存优势:NVIDIA RTX PRO 6000 Blackwell 系列的 96GB 内存是一个显著的优势,与 NVIDIA RTX 6000 Ada 相比,它可以使模拟单元数量翻倍。
-
强大的扩展性:与 NVIDIA RTX 6000 Ada GPU 相比,NVIDIA RTX PRO 6000 Blackwell 系列显示出更好的强大扩展性能,以更小的问题规模达到最大性能。
-
实际优势:性能优势减少了总仿真时间,更高的 VRAM 增加了仿真模型的大小。
以下是配置工程计算解决方案的一些注意事项:
AMD 还是 Intel CPU 更适合 Pacefish?
Pacefish 对英特尔或 AMD 处理器没有偏见。Pacefish 可在两个平台上运行,性能差异可以忽略不计。
Pacefish 的系统内存要求是什么?
主机系统的 RAM 与 VRAM 比率应为 3:1。例如,对于两个 NVIDIA RTX PRO 6000 Blackwell GPU,每个 96GB(总共 192GB),平台理想情况下应具有 576GB 的 RAM。RAM 低于理想值不会造成问题,但大多数生产运行都需要统计后处理结果。
统计数据集通常消耗的主机内存量是 GPU 上瞬态模拟状态所消耗的两倍。可用主机内存较少可能会限制单元计数中的生产运行,导致系统在设置即将消耗所有可用 VRAM 之前提前耗尽内存。
在哪里购买配置了 NVIDIA RTX PRO 6000 Blackwell 的系统?
联泰集群是一家高性能计算解决方案提供商,可构建定制的多 GPU 工作站、GPU 计算服务器和完整的计算集群。立即联系我们,与我们的销售工程师联系,以配置您理想的 CFD 工程解决方案。





相关贴子
-
 基准
基准GPU 加速流体和粒子模拟-使用 Enginsoft 进行 Particleworks 基准测试
2025.01.10 28分钟阅读 -
 基准
基准AlphaFold2 GPU 基准测试和硬件建议
2023.12.08 10分钟阅读 -
 基准
基准GeForce RTX 4090 RELION Cryo EM 基准测试和分析
2023.01.11 45分钟阅读