
博客
W5232 G3V4 智能工作站:助力企业突破算力瓶颈,实现降本增效

在当今智能时代,算力已成为推动各行业发展的关键生产力。然而,许多企业在面对大模型训练、自动驾驶仿真测试、影视渲染等各类新型和传统复杂任务时,常常因算力不足而陷入瓶颈。如何突破这一限制,成为众多企业和机构亟待解决的问题。今天,我们为您带来一款破局利器——W5232 G3V4 智能工作站。它不仅能解决您的算力瓶颈问题,还能为您带来显著的效益提升。
W5232 G3V4 智能工作站搭载双路 Intel 第 4/5 代至强处理器,单路最高功耗可达 385W。这意味着即使在高负载场景下,工作站也能保持稳定运行,显著提升计算密集型任务的处理能力。无论是复杂的 AI 模型训练,还是大规模的数据分析,都能轻松应对。帮助客户缩短任务处理时间,提高工作效率,从而更快地实现项目交付和收益增长。
16 通道 DDR5 ECC 内存,提供高达 4TB 的海量空间,配合 4 盘位 U.2/SAS 混插架构,能够满足不同数据存储需求。ECC 纠错机制有效降低数据错误率,确保长时间稳定运行。同时,SAS HDD 可用于存放备份和归档数据,NVMe SSD 则专注于处理热数据,优化了成本与性能的平衡。帮助客户减少因数据错误导致的项目延误和成本损失,同时降低存储成本,提升整体性价比。
最大可支持两块 600W GPU,或一块三涡轮 600W GPU,这使得 W5232 G3V4 智能工作站在多个专业领域都能展现核心价值。无论是 AI 研发中的深度学习任务,还是影视特效制作中的复杂渲染,都能提供强大的图形处理能力。帮助客户提升专业领域的竞争力,实现更高质量的成果输出,为企业带来更高的附加值。
搭配纳米晶结构材料自研机箱,银色外观设计,不仅美观大方,更凭借精湛的工艺和极高的加工密度,比市场上大多数普通铁皮机箱更加结实耐用。这不仅提升了产品的使用寿命,也彰显了高端品质。帮助客户减少设备更换频率,降低长期使用成本,同时提升企业形象。
对于 AI 研发企业来说,W5232 G3V4 智能工作站能够将千亿级大模型训练周期压缩至 7 天,支持 DeepSeek R1 量化模型本地化部署。双 GPU 全功率释放,配合液冷散热技术,确保 600W 双宽卡持续稳定输出算力。这不仅大大缩短了研发周期,更降低了研发成本,助力企业在激烈的市场竞争中脱颖而出。
在自动驾驶领域,W5232 G3V4 智能工作站能够将仿真测试效率提升3倍,支持50路传感器实时融合处理。PCI-e 5.0 通道实现毫秒级延迟,NVMe 存储百万 IOPS 加速场景重建,为自动驾驶技术研发提供了强大的技术支持,助力企业加速自动驾驶技术的落地应用。
对于高校科研机构,W5232 G3V4 智能工作站开箱即用,预装 PyTorch/TensorFlow 加速套件,搭配联泰集群自研 AI 管理系统,能够快速搭建 AI 实验环境,帮助科研人员专注于研究工作,提高科研效率,加速科研成果转化。
在影视特效制作领域,W5232 G3V4 智能工作站能够将 4K 渲染效率提升 40%,支持实时光线追踪。双 GPU 与 16 通道内存带宽的组合,能够流畅处理 8K 素材流,大大缩短了影视特效制作周期,提升了制作效率,为影视行业带来了更高的创作自由度。
在医疗领域,W5232 G3V4 智能工作站能够将医疗影像分析速度提升 50%。ECC 内存纠错机制确保基因组数据的完整性,为医疗诊断和研究提供了更准确、更可靠的数据支持,助力医疗机构提升医疗服务水平。
对于金融科技行业,W5232 G3V4 智能工作站能够将高频交易响应时间控制在小于 0.1ms,风控模型训练效率翻倍。DDR5-5600MHz 内存带宽提升 50%,有效压缩了量化计算延迟,为金融机构提供了更快速、更精准的交易决策支持,助力企业在金融市场中把握先机。
W5232 G3V4 智能工作站不仅在硬件配置上表现出色,还针对不同行业提供定制化的解决方案。无论是 AI 研发、自动驾驶、高校科研、影视特效、医疗还是金融科技,我们都能根据您的具体需求,为您量身定制最适合的方案,确保您在使用过程中能够充分发挥工作站的强大性能,实现业务的高效发展。可以使客户获得最适合自身业务需求的解决方案,避免资源浪费,提升投资回报率。





相关贴子
-
 人工智能与大模型
人工智能与大模型要规避的7个常见的机器学习和深度学习错误和限制
2023.02.21 30分钟阅读 -
 人工智能与大模型
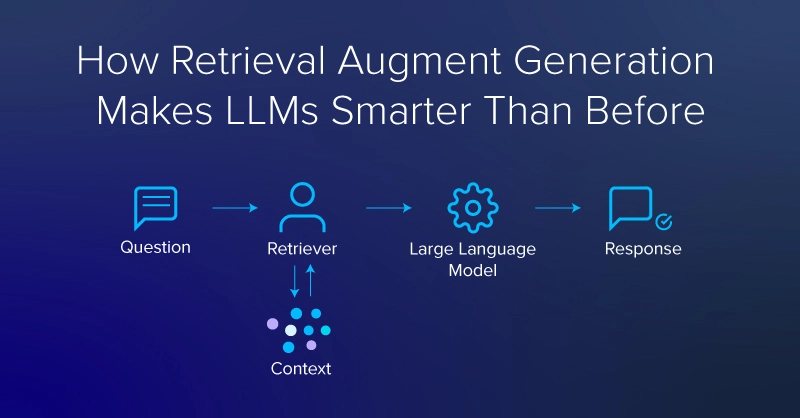
人工智能与大模型检索增强生成如何使 LLM 比以前更智能
2024.08.23 32分钟阅读 -
 人工智能与大模型
人工智能与大模型为什么 Edge AI Inferencing 对人工智能的未来至关重要
2025.05.09 22分钟阅读