
博客
BERT 转换器原理详解

BERT 改变了机器解读人类语言的方式。其全称为 “双向编码器表征转换器”(Bidirectional Encoder Representations from Transformers),通过双向读取文本让模型理解上下文语境。尽管 BERT 并非如今大型语言模型(LLMs)的核心焦点,但它仍是一项广泛应用的人工智能技术。
BERT 推出后,迅速成为自然语言处理(NLP)任务的基准模型。这类任务严重依赖深度注意力机制,需要高吞吐量的计算能力。高效训练或微调 BERT 通常依赖于支持大规模矩阵运算并行化的 GPU 加速服务器。
本文将详细介绍 BERT 的架构、训练方式、常见应用场景,并提供硬件配置建议。
BERT 基于 Transformer 架构,但对“自注意力机制”做了关键优化:
-
双向编码:传统 Transformer 是单向(如 GPT 仅看左侧上下文),BERT 通过 Masked Language Modeling(MLM)和 Next Sentence Prediction(NSP)任务,让模型同时学习左侧和右侧上下文,实现“双向理解”。 -
分层结构:由多层 Transformer 编码器堆叠而成,每层包含“多头自注意力”和“前馈神经网络”模块,逐层提取文本的语义特征。
两种版本均表现出优异性能,但 BERT Large 虽能提供更出色的语言理解能力,却需要更高的计算资源和内存支持。在大型数据集上微调 BERT Large 时,很容易耗尽多 GPU 工作站或高显存节点的资源。
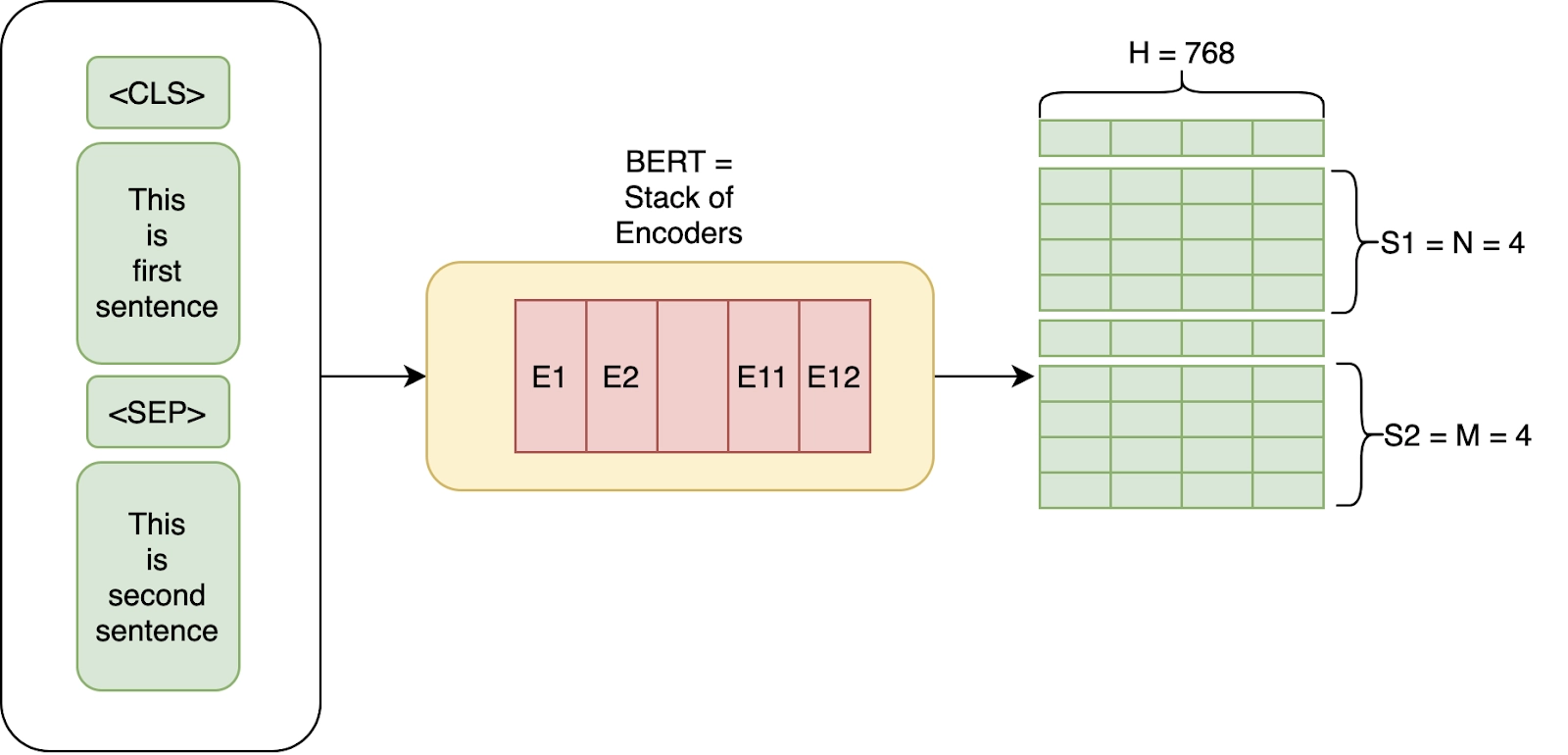
BERT 的核心功能是将每个标记(单词或子词)转换为 768 维向量,该向量能够表征标记在上下文语境中的含义。通过微调,这些嵌入向量可应用于多个下游任务:
-
情感分析:将评论分类为正面、负面或中性; -
问答系统:定位文本中与问题最相关的片段作为答案; -
命名实体识别(NER):识别文本中的专有名词、机构名称或地点信息。
由于 BERT 基于海量文本语料库进行预训练,因此在适配新任务时,仅需少量标注数据即可完成微调。不过,微调过程仍涉及大量重新训练工作,因此高性能 GPU 或多核 CPU 对于缩短训练时间至关重要。查看我们的深度学习基准测试,其中包含 BERT Base 和 BERT Large 的相关测试结果!
BERT 基于 Transformer 编码器构建,这是一种深度神经网络架构,通过自注意力机制理解单词之间的关联。与循环神经网络(RNNs)或长短期记忆网络(LSTMs)按顺序处理文本不同,BERT 能并行处理所有标记,并同步捕捉整个序列中的依赖关系。
每个 Transformer 编码器层包含三个主要操作:
-
多头自注意力(Multi-Head Self-Attention):让 BERT 能够权衡不同单词之间的相对重要性; -
前馈网络层(Feedforward Layers):通过非线性变换优化上下文语义; -
残差连接与归一化(Residual Connections and Normalization):确保深度堆叠层的稳定性和梯度流动。
这些编码器经过反复堆叠,构成了 BERT 的深度上下文网络。
现代 BERT 模型
自 BERT 发布以来,研究人员开发了多种优化版本,如 DistilBERT、ALBERT 和 RoBERTa,这些模型通常被称为 “现代 BERT 模型”。它们保留了 Transformer 的核心结构,同时着重提升效率和训练效果:
-
DistilBERT:体积更小、速度更快,通过知识蒸馏技术训练而成; -
ALBERT:通过跨层权重共享减少参数量; -
RoBERTa:通过延长训练时间和动态掩码技术提升性能。
在实际任务中,选择 BERT Base、BERT Large 还是现代变体,需根据可用计算资源和延迟要求决定。文档检索、对话式 AI 等对准确率要求较高的任务,适合在 GPU 加速服务器上运行大型架构;而边缘部署或延迟敏感型场景,则更倾向于选择蒸馏模型。
BERT 不直接接收原始文本作为输入,而是依赖结构化的分词格式,以处理多个句子及其之间的关联。
分词(Tokenization)
第一步是词片分词(WordPiece tokenization),将文本拆分为子词单元。这种方式既能控制词汇表规模,又能有效处理生僻词或未登录词。例如,单词 “playing” 可能被拆分为 “play” 和 “##ing”,确保 BERT 能够理解 “plays”“played”“player” 等词根衍生词。
特殊标记(Special Tokens)
BERT 会添加特定标记以帮助模型理解句子结构:
-
[CLS](分类标记):添加在每个输入的开头,其输出表征用于分类任务; -
[SEP](分隔标记):标记句子结尾,或在问答、下一句预测等任务中分隔句子对。
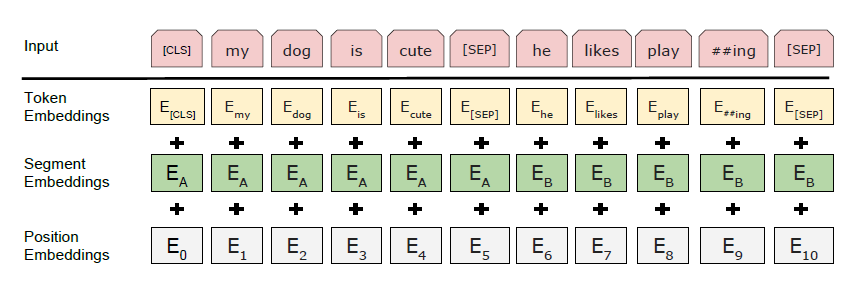
例如,句子经过处理后会变为:
"My dog is cute. He likes playing."

输入嵌入(Input Embeddings)
每个标记的表征由三种习得的嵌入向量组合而成:
-
标记嵌入(Token Embeddings):捕捉单个单词或子词的含义; -
段落嵌入(Segment Embeddings):在句子对任务中区分句子 A 和句子 B; -
位置嵌入(Position Embeddings):保留单词顺序,弥补 Transformer 无法按顺序处理序列的缺陷。
每个标记的最终输入向量是这三种嵌入向量的总和。这种复合输入使 BERT 能够同时理解文本的含义和结构。
BERT 的训练过程是其独特优势的核心所在。它并非单向学习语言模式,而是同时从一个单词的两侧获取信息。预训练阶段基于维基百科(Wikipedia)、BooksCorpus 等海量文本语料库进行,在针对特定任务微调前,已形成对语言的深度上下文理解。
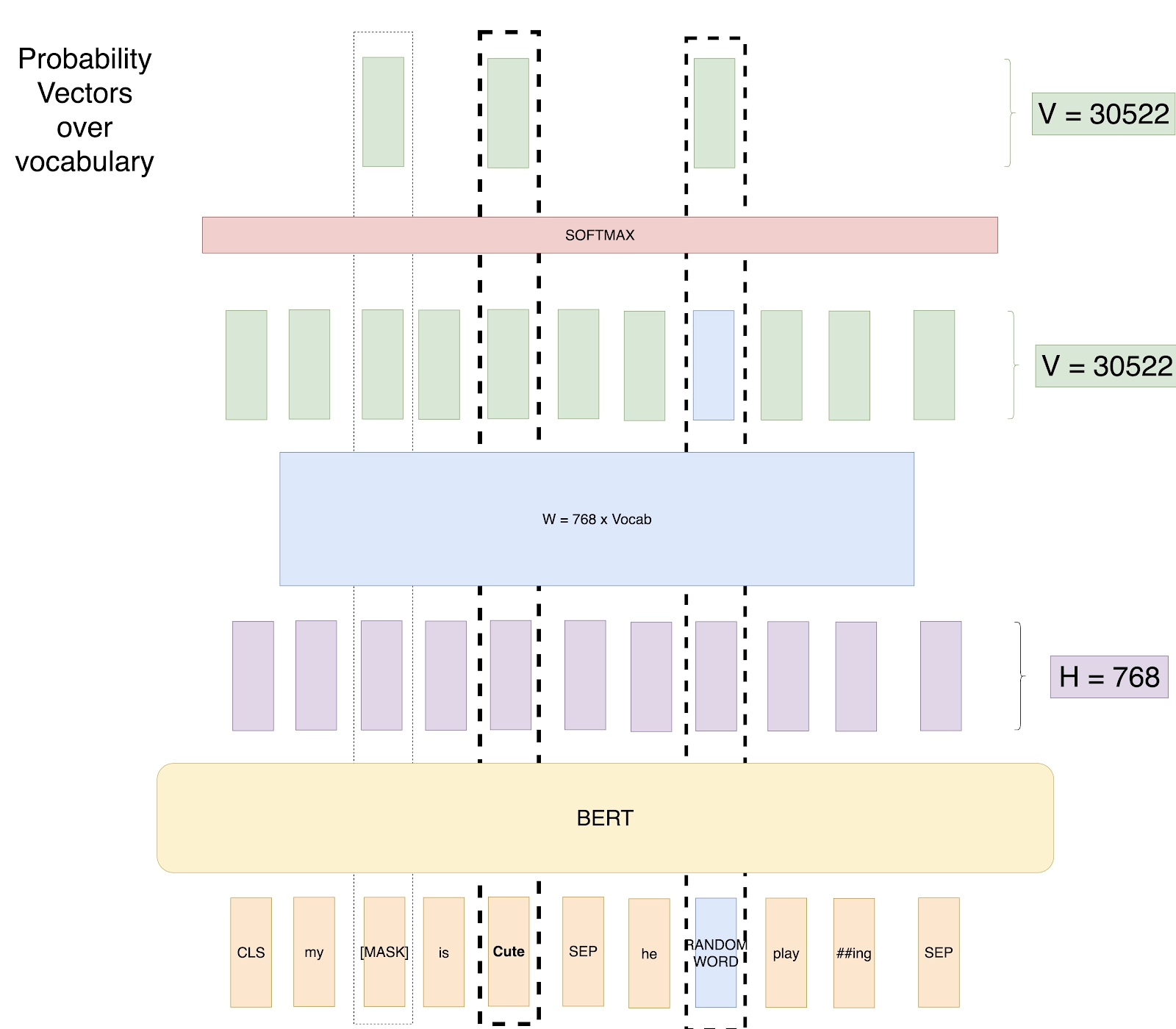
a. 掩码语言模型(MLM)
BERT 通过学习预测句子中缺失的单词进行训练。训练时,约 15% 的标记会被选中用于预测,具体策略如下:
-
80% 的选中标记替换为 [MASK] 标记; -
10% 的选中标记替换为随机单词; -
10% 的选中标记保持不变。
这一机制迫使模型通过上下文推断词义,而非死记硬背单词。例如:“My [MASK] is cute(未掩码). He [随机单词] playing.”
BERT 会根据上下文预测掩码位置的单词可能是 “dog” 或 “cat”。这种方法实现了双向学习,使 BERT 能够以传统单向模型无法企及的方式理解单词间的关联。
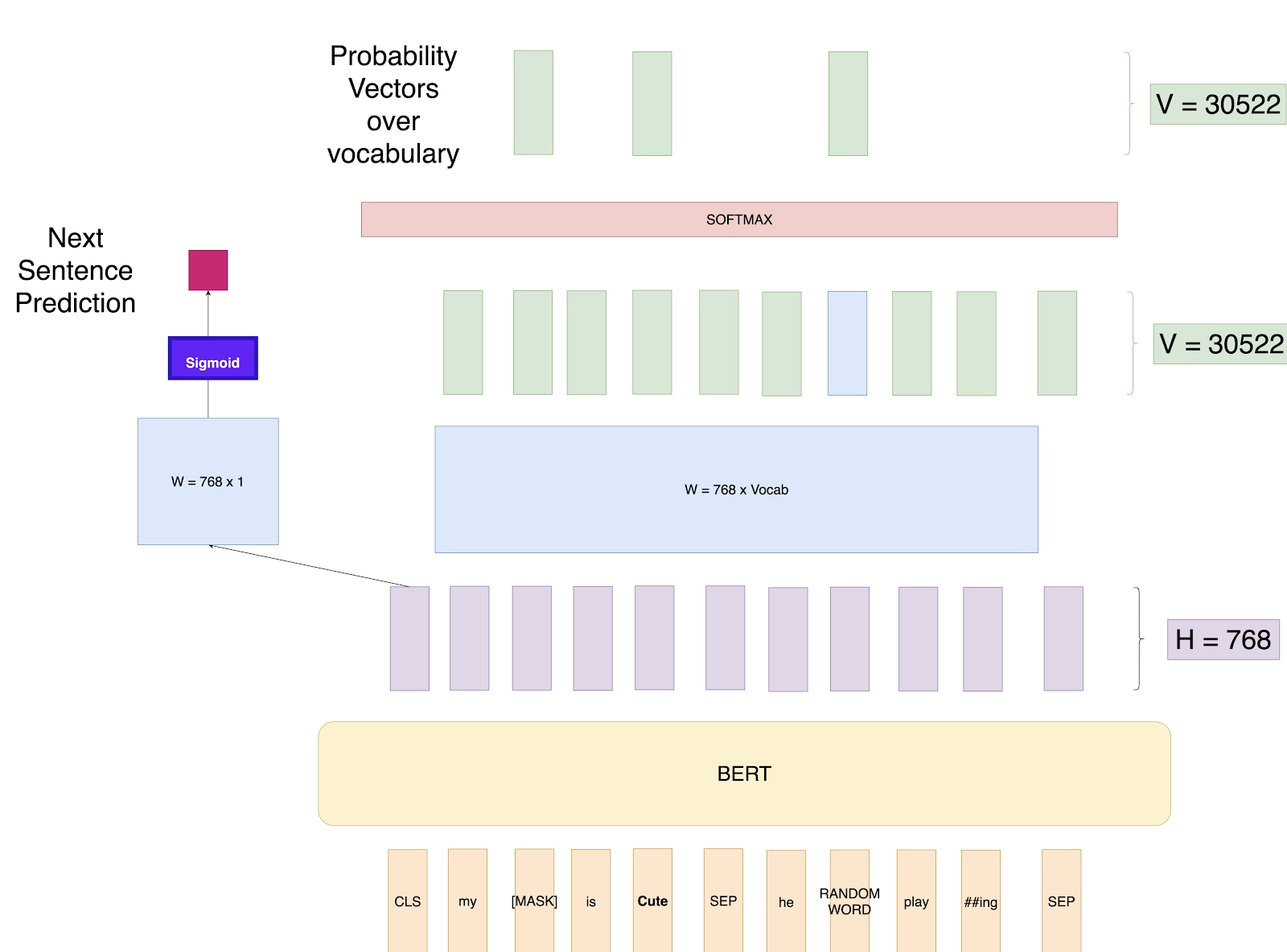
b. 下一句预测(NSP)
除掩码语言模型外,BERT 还会学习句子之间的关联。在该任务中,模型会接收两个句子:
-
50% 的概率下,第二个句子是第一个句子的真实下一句; -
50% 的概率下,第二个句子是随机抽取的无关句子。
模型需要预测第二个句子与第一个句子是否存在逻辑关联。下一句预测任务提升了 BERT 处理问答、阅读理解等涉及句子关系的任务的能力。
从头训练 BERT 对资源要求极高。例如,BERT Large 是在谷歌 TPU 上训练的,动用了数百个核心进行并行运算。大规模复现这类训练需要满足以下条件:
-
高带宽互联技术(如 NVLink 或 InfiniBand),用于同步大型模型的梯度; -
优化支持混合精度矩阵运算的 GPU 或加速器; -
每个节点配备充足内存,以容纳长输入序列。
在消费级 GPU 上运行 BERT Base 是可行的,但 BERT Large 及具有长上下文窗口的现代 BERT 变体,其内存占用可能超过 20GB。我们推荐使用 NVIDIA RTX PRO Blackwell 系列 GPU:
-
NVIDIA RTX PRO 6000 Blackwell:配备 96GB GDDR7 显存; -
NVIDIA RTX PRO 5000 Blackwell:提供 48GB GDDR7 和 72GB GDDR7 两种版本。
优化推理过程通常会利用张量核心 GPU 或支持混合精度的加速器,在不影响准确率的前提下保证吞吐量。对于部署大规模 NLP 任务的机构而言,多 GPU 集群或专用推理服务器是维持实时性能的关键。
即使是在特定领域数据集上进行微调,也可能需要数小时甚至数天时间,具体取决于序列长度和模型变体。对于研究机构或企业来说,结合预训练检查点与可扩展 GPU 服务器,是发挥 BERT 能力的最实用方案。
预训练完成后,通过添加轻量级的任务专用层并对整个模型进行微调,即可将 BERT 适配到特定任务中。这种灵活性使其适用于各类企业级 NLP 应用场景。
微调所需数据量较少,但仍需要较高的计算吞吐量:
-
BERT Base 可在单 GPU 上高效完成微调; -
BERT Large 拥有 3.4 亿参数量,借助多 GPU 并行计算可显著提升效率; -
RoBERTa、DistilBERT 等现代 BERT 变体,在准确率、速度和硬件成本之间实现了平衡。
大规模部署 BERT 任务时,需结合 GPU 服务器或推理加速器,并使用 TensorRT、ONNX Runtime 等优化深度学习框架。
常见应用场景
-
文本分类:在 [CLS] 标记的输出上添加线性层,实现情感、意图等类别的预测; -
命名实体识别(NER):在每个上下文嵌入向量上通过 Softmax 层,为每个标记预测标签(如人物、机构、地点等); -
问答系统:确定段落中答案片段的起始和结束位置。该任务通过两个可训练向量对每个标记位置进行评分。
这些任务均受益于 BERT 的深度上下文嵌入向量 —— 该向量已整合了预训练阶段习得的语法和语义信息。
BERT 为自然语言理解树立了新标杆,并持续影响着如今各大 NLP 架构的发展。其基于 Transformer 的设计实现了深度上下文推理,在几乎所有语言任务中都优于传统嵌入模型。
需重点记住的核心要点:
-
BERT 通过掩码语言模型和下一句预测任务,实现双向语义学习; -
其 Transformer 编码器架构能够并行捕捉所有标记的上下文关联; -
微调特性使 BERT 可适配几乎所有 NLP 任务,从文本分类到问答系统均适用; -
硬件选择至关重要 —— 训练和推理效率与 GPU 性能、内存带宽及互联速度密切相关。
对于部署 NLP 系统的机构而言,投资高性能 GPU 服务器或集群,能确保 BERT 及其后续模型以最高效率提供实时洞察。无论是科研工作、AI 驱动的客户支持,还是内容智能分析,优化的基础设施都是充分释放 Transformer 模型潜力的关键。





相关贴子
-
 技术分享
技术分享AlphaFold 更新显著提高了对接、核酸和 PTMS 的准确性
2024.04.12 14分钟阅读 -
 技术分享
技术分享智能体 AI 平台的硬件基础设施架构设计
2026.03.27 77分钟阅读 -
 技术分享
技术分享如何加速工业产品设计中的原型制作
2024.12.13 33分钟阅读