
博客
智能体 AI 平台的硬件基础设施架构设计

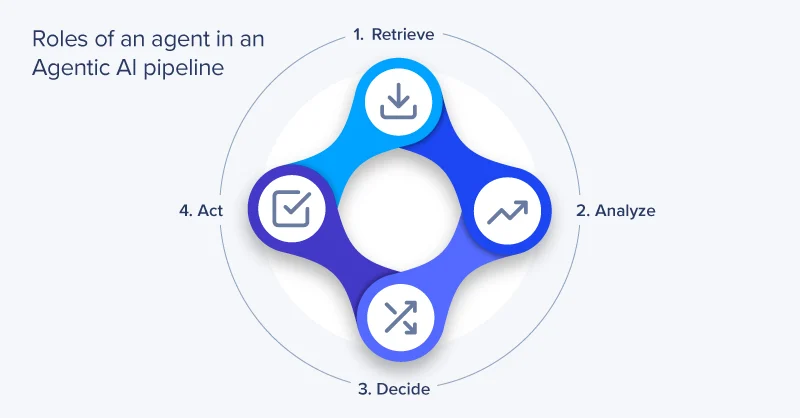
智能体人工智能(Agentic AI)流水线是一种计算架构,由多个专业化 AI 智能体协同合作,完成复杂任务。流水线中的每个智能体各司其职,例如数据检索、数据分析、决策制定或指令执行,通过协同配合达成整体目标。
简而言之,本地部署的优势如下:
- 性能优势:智能体可就近调用企业数据与计算资源
- 协同高效:依托轻量级 API 或消息总线实现智能体间通信
- 极速响应:通过降低延迟提升决策效率
- 可控性强:对企业专有数据实施严格治理
- 成本可控:自有基础设施带来稳定的运营成本
- 自主独立:不依赖外部云服务供应商
本文将深入探讨本地 GPU 部署的优势,呈现其高层架构视图,阐释智能体编排与通信机制,分析性能优化模式,评估经济层面考量因素,并提供切实可行的落地启动策略。
智能体人工智能流水线中的各智能体,是功能独立的专业化服务模块,各自承担整体工作流中的特定环节。
- 数据检索:该类智能体从数据库、数据流或文档库等多源渠道,获取并提取相关信息;
- 数据分析:数据检索完成后,分析类智能体对数据进行处理与解读,识别与任务相关的模式、异常点及核心洞察;
- 决策制定:决策类智能体基于分析后的数据,应用推理模型、业务逻辑或训练习得的策略,确定最优行动方案;
- 指令执行:执行类智能体负责完成最后环节,例如触发业务流程、更新记录系统、发送通知或生成报告。
在复杂的企业级工作流中,多智能体架构的性能显著优于单一的单体式 AI 模型,原因在于各环节的模型均针对专项任务实现了功能专精。同时,该架构支持任务并行执行,可对单个组件进行针对性扩容。
多智能体架构的核心优势还体现在三方面:
- 效率提升:多智能体并行处理任务,大幅缩短复杂流程的整体耗时;
- 系统韧性:单个智能体故障不会导致整个流水线瘫痪,系统可设计故障绕行或步骤重试机制,提升整体稳定性;
- 可追溯性:每个智能体的操作与决策均可独立记录日志,形成清晰详尽的追踪链路,满足合规审计、治理管控与故障调试的需求。尽管 AI 系统仍存在 “黑箱” 特性,但可精准定位具体模型的出错环节。
将智能体人工智能流水线部署于本地 GPU 集群,具备以下显著优势:
- 数据主权保障:所有数据处理均在企业内网环境完成,确保满足隐私保护、数据驻留及合规治理的相关要求;
- 成本可预测性:在稳定的资源利用率下,固定的基础设施成本相比波动的云 GPU 租用费用,具备更高的经济性;
- 延迟稳定可控:硬件设施就近对接数据源与终端用户,减少网络延迟,实现智能体的实时响应;
- 定制化优化空间:企业可根据自身工作负载特征,对硬件配置、网络架构及管理策略进行针对性调优。
一套基于 GPU 的本地智能体人工智能系统,通常分为多个功能分层,各层各司其职,共同支撑流水线的稳定运行。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
该架构的设计遵循以下核心原则,以保障系统的可扩展性、安全性与可管理性:
- 容器化封装:每个智能体均以容器(如 Docker)形式打包,确保跨集群部署的可移植性、资源隔离性与一致性;
- 统一策略管控:安全与合规策略采用集中式定义,由编排层统一执行,确保所有智能体均符合治理标准;
- 全链路监控:搭建一体化的监控与日志系统,追踪整个集群的健康状态、性能表现与资源消耗情况,为运维团队提供全面可视性;
- 数据与模型就近部署:将机器学习模型及其所需数据集,存储在靠近 GPU 服务器的位置,最大限度减少数据传输开销,降低延迟。
在智能体流水线中,协同开销(包括网络跳转、数据序列化及重试机制)可能成为比 GPU 原始吞吐量更突出的性能瓶颈。因此,通信与上下文管理层的设计,需满足低延迟、水平扩展与可调试的核心要求。
一、 选择适配的通信模式
- 请求 / 响应模式(REST、gRPC)
- 异步 / 事件消息模式(Kafka、消息总线)
二、 优化共享上下文管理,降低 “影响范围”
为减少带宽占用、缓解内存压力、保障集群的规模化高效运行,应避免在智能体间传输大型数据载荷,建议采取以下策略:
- 共享指针而非数据集:传递数据的 ID、统一资源标识符(URI)、哈希值或向量嵌入,替代原始文档;
- 按需获取数据:下游智能体仅在需要时,才调取完整数据内容。
三、 构建高可靠性与高可视性机制
- 可靠性保障:通过设置超时机制、带退避策略的有限重试次数及熔断器模式,防止单个智能体故障导致整个流水线停滞;
- 可视性保障:借助分布式追踪(跨环节传递追踪 ID)、结构化日志及延迟与错误指标监控,精准定位瓶颈来源(网络、编排层或 GPU 推理环节)。
以下方法经实践验证,可有效提升本地部署智能体流水线的吞吐量、降低延迟、优化运行效率:
-
智能体与数据、模型就近部署
-
预加载并锁定高频模型
-
请求批量处理
-
GPU 资源分片管理
-
异步消息通信
若跳出单纯的计算成本维度,从更全面的视角分析,本地部署模式的经济优势将十分显著。尽管云服务的入门门槛低,初期投入少,且能灵活应对突发工作负载,但智能体人工智能的长期云服务成本会快速攀升。因此,企业应优先采用本地部署方案保障高利用率场景下的需求,同时搭配混合云架构,应对临时性的计算峰值。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
本地 GPU 集群为企业部署智能体人工智能流水线,搭建了兼具安全性、高性能与成本可控性的坚实底座。企业通过自主掌控基础设施、数据资源与工作负载优化策略,可构建完全贴合自身需求的系统,同时规避纯云部署模式下成本不可预测、延迟波动大的痛点。
本文阐述的架构模式、通信策略与经济性考量,为设计可扩展、高效率的智能体人工智能部署方案提供了清晰路线图。云资源在应对峰值溢出负载与技术验证场景时仍具价值,但对于生产级智能体人工智能系统的核心部分而言,本地基础设施的稳定性与可控性优势更为突出。
您是否已准备好为智能体人工智能升级计算基础设施? 联泰集群提供从单台计算节点到整机架规模的定制化解决方案。立即联系我们的工程师,开启您的智能体 AI 部署之旅!





相关贴子
-
 技术分享
技术分享深度解析 | 新型智算中心技术构建中 AI 大模型应用的建设
2024.07.11 86分钟阅读 -
 技术分享
技术分享多站点分布式 GPU 架构:探索本地分布式 GPU 资源
2025.12.12 49分钟阅读 -
 技术分享
技术分享DGX Spark 硬件下三大推理引擎实测对比:Ollama、vLLM、DS4
2026.07.10 34分钟阅读