
博客
GPU 深度学习性能大比拼:BERT、GNMT 等模型实测数据


虽然这些测试负载和您实际的工作负载可能不完全一样,但它们能帮您很好地了解不同 GPU 之间的相对性能。
我们会不断测试更多 GPU,让这篇内容越来越丰富。目前已测试的 NVIDIA GPU 包括:
-
RTX PRO 6000 Blackwell Max-Q 96GB GDDR7 -
RTX 6000 Ada 48GB GDDR6 -
L4 系列 48G GDDR6
我们的测试用了一套深度学习基准测试套件,涵盖了真实世界中的 AI 工作负载,包括:
-
BERT 基础版 / 大型版:自然语言处理和 Transformer 模型 -
GNMT(谷歌神经机器翻译):序列到序列的翻译模型 -
ResNet50:计算机视觉领域的图像分类模型 -
TransformerXL 基础版 / 大型版:用于文本序列建模和上下文理解的高级自然语言处理模型 -
Tacotron2:文本转语音合成模型 -
WaveGlow:高质量音频生成模型 -
SSD(单发多框检测器):计算机视觉中的目标检测模型 -
神经内容过滤(NCF):推荐系统模型
这些性能数据不能只看表面数值,而应作为相似工作负载中性能对比的参考。我们挑选了多样的负载,涵盖视觉、Transformer 和分类模型。
-
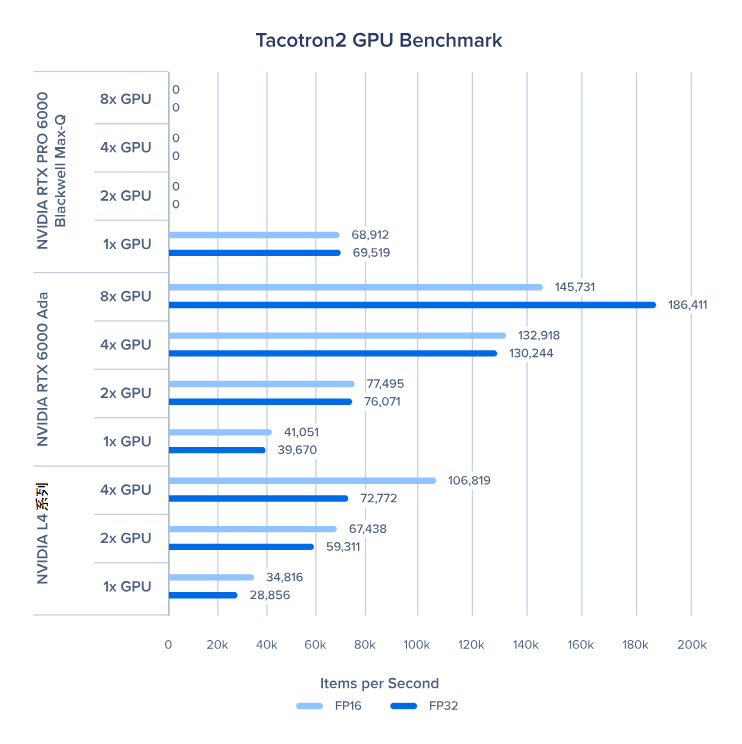
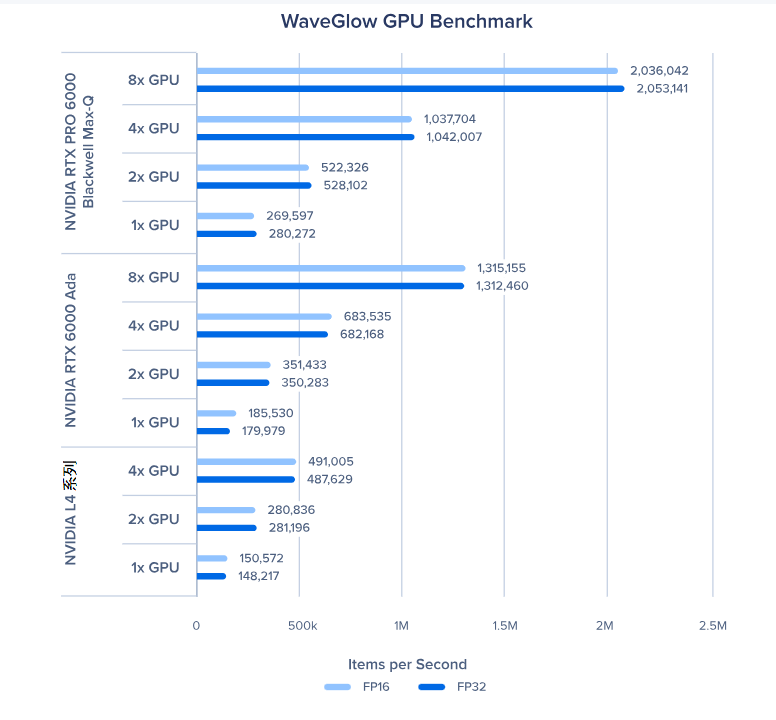
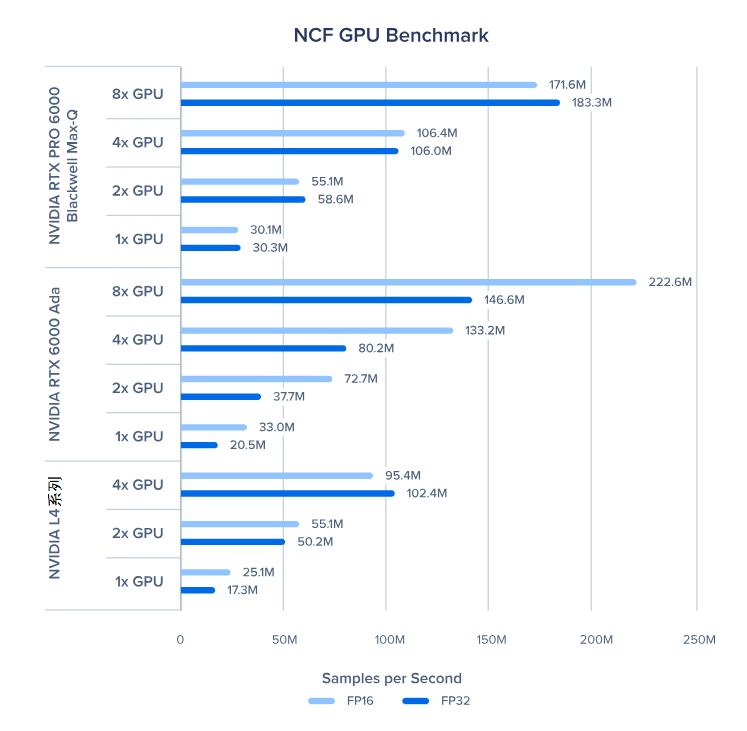
GPU 的扩展性相当不错,虽然有一点性能损耗,但加速比和 GPU 数量几乎能达到 1:1。不过在 Tacotron2、TransformerXL 大型版和 NCF 这类工作负载中,GPU 扩展性会受影响。这很可能是因为这些负载的批量较小,需要频繁从内存中读取数据。
-
NVIDIA Blackwell 的性能远超 NVIDIA Ada,在某些场景下(如 ResNet50、WaveGlow、SSD 和 NCF)性能甚至能翻倍。更大的内存让模型和数据能直接存放在内存中,减少了内存带宽瓶颈。
-
RTX 6000 Ada 和 L40S 性能非常接近,因为它们采用相同的 GPU 架构和核心。不过在一些负载中,两者的性能会有小幅波动,互有胜负。
-
多 GPU 的 NVIDIA RTX PRO 6000 Blackwell 在 Tacotron2 测试中显示为 DNR(未运行),这是我们测试时出现的错误,后续会修复,并非性能问题。
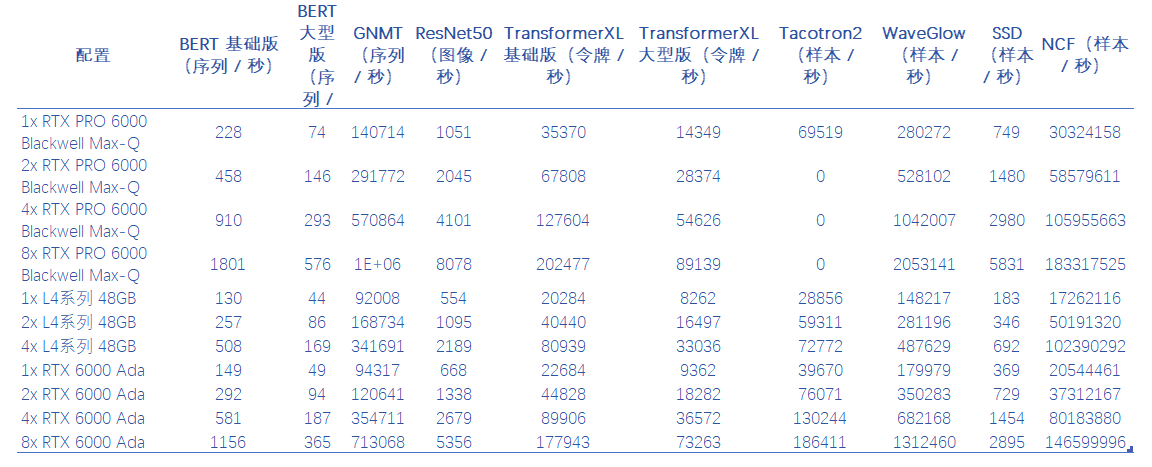
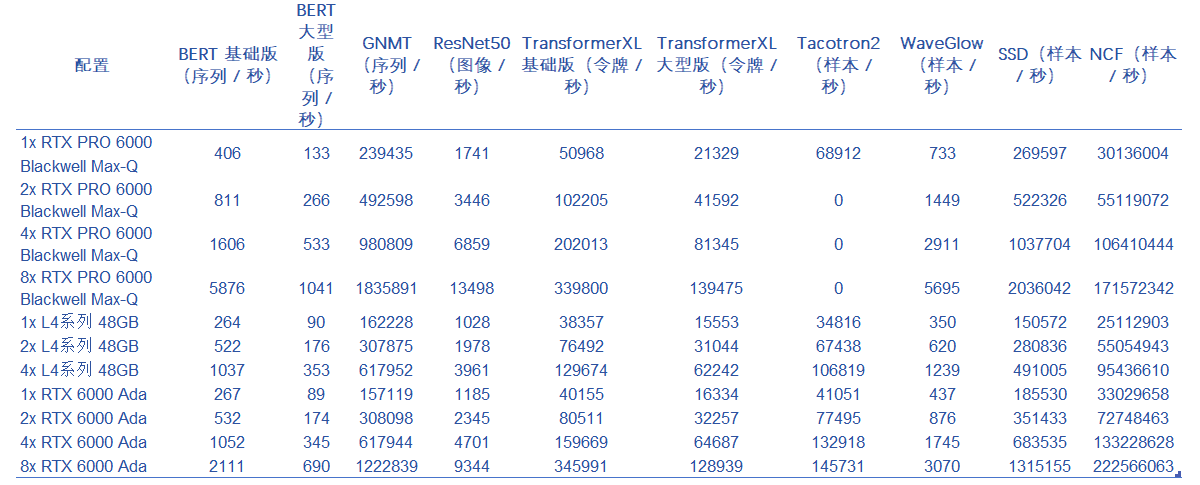
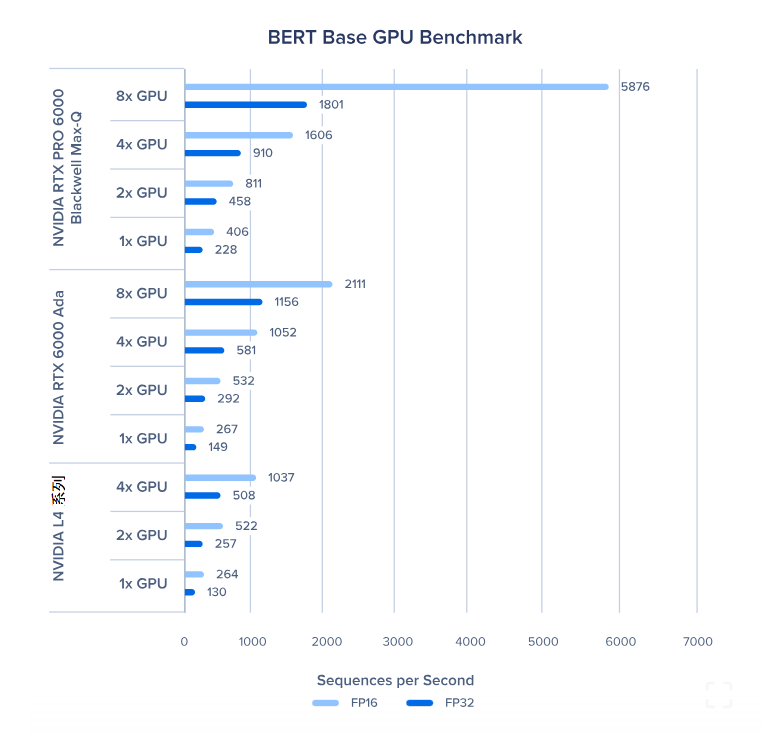
BERT 基础版 GPU 基准测试
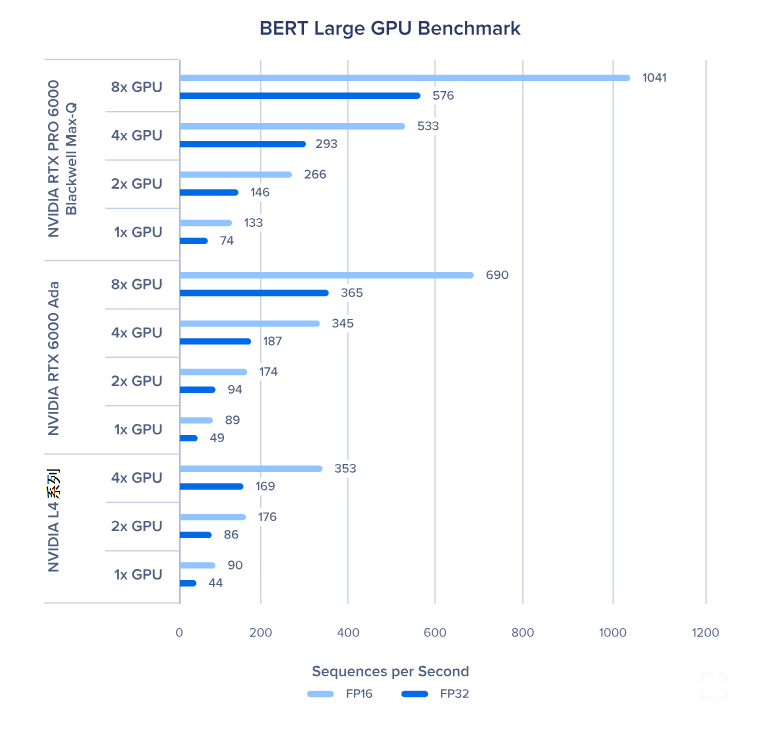
BERT 大型版 GPU 基准测试
ResNet50 GPU 基准测试
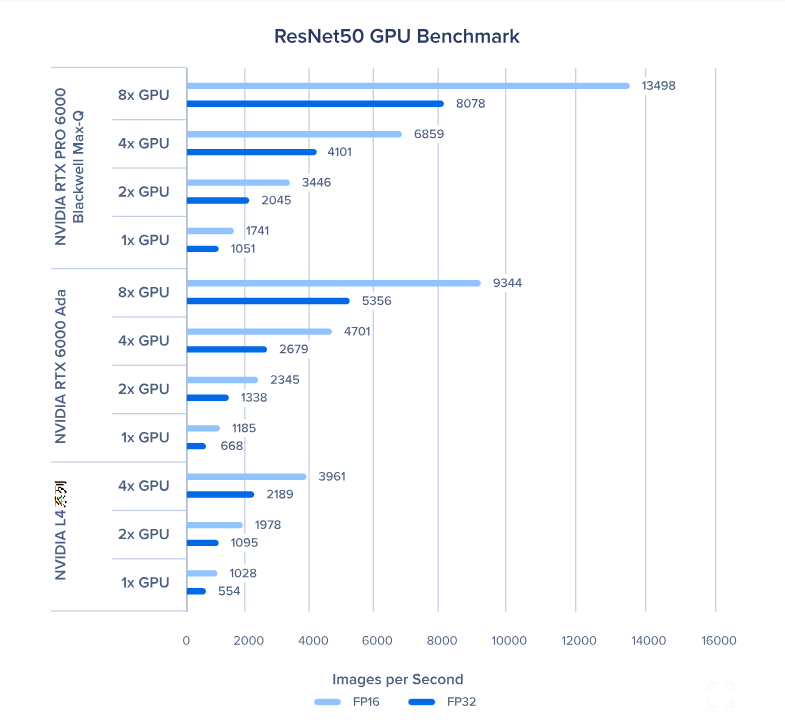
GNMT GPU 基准测试
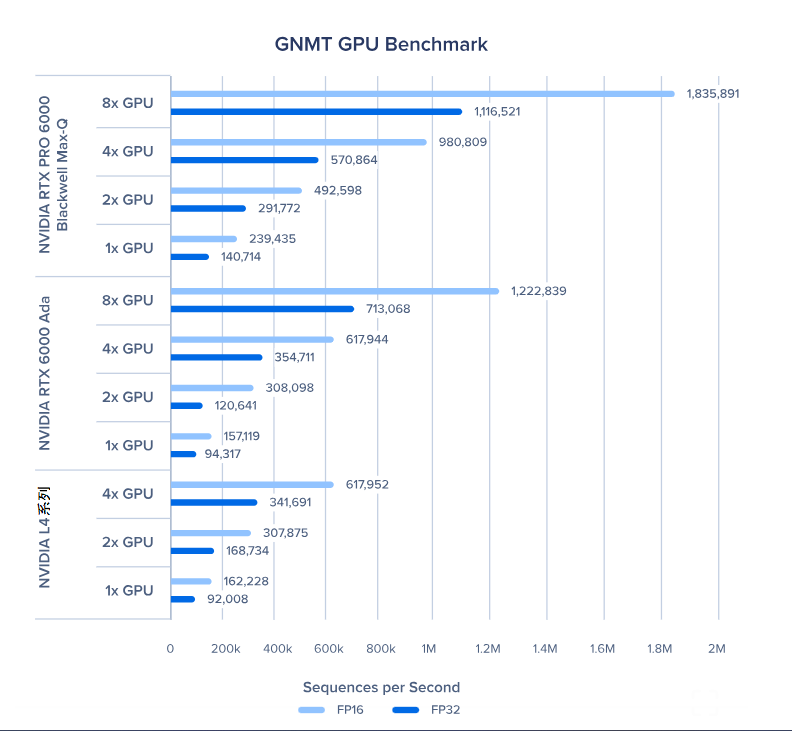
TransformerXL 基础版 GPU 基准测试
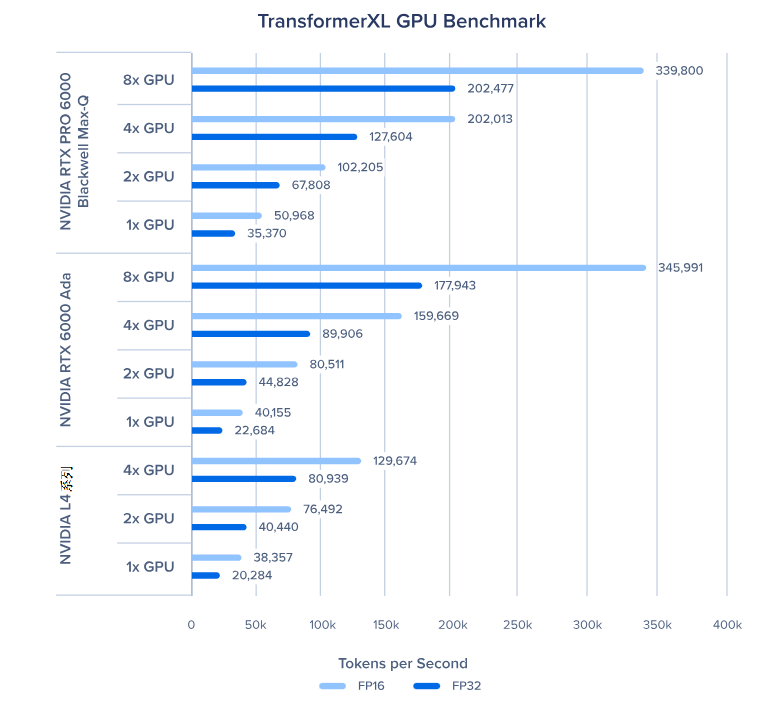
TransformerXL 大型版 GPU 基准测试
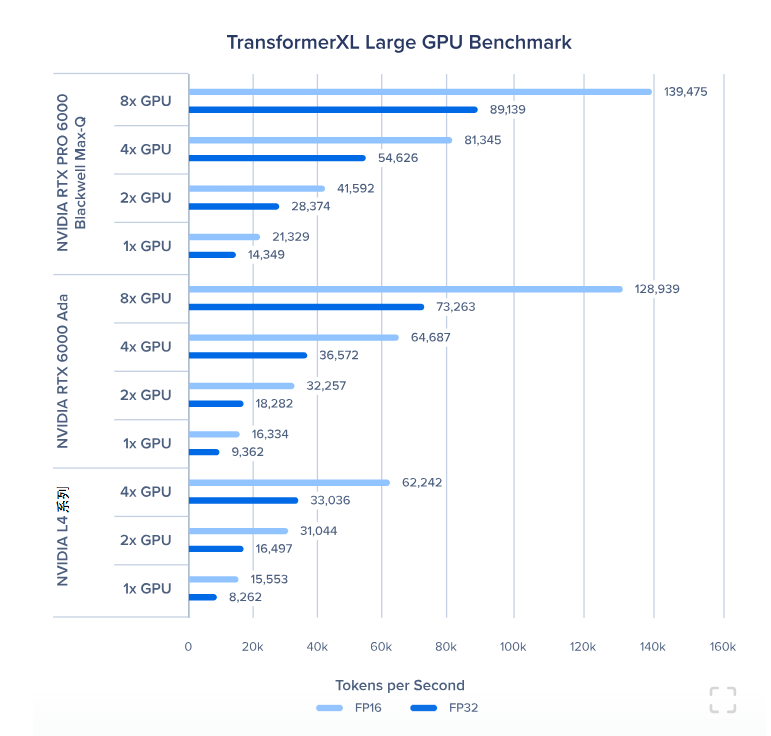
Tacotron2 GPU 基准测试
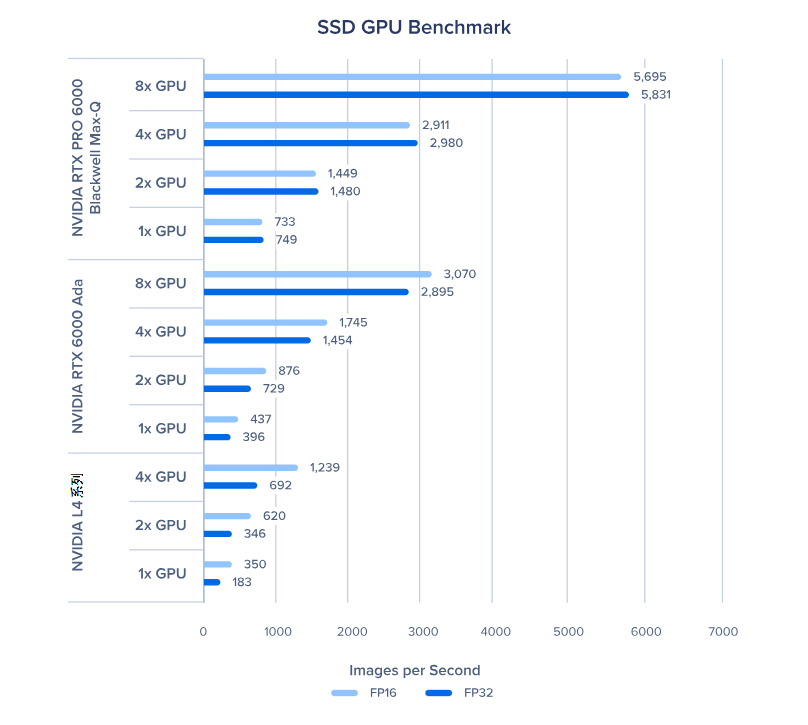
单发多框检测器(SSD)GPU 基准测试
WaveGlow GPU 基准测试
神经内容过滤(NCF)GPU 基准测试
下面我们来看看相对单 GPU 性能的扩展效率。我们取了 3 款 GPU 的平均值来计算扩展性,这能告诉我们哪些工作负载能从多 GPU 中获益更多。

这里我们来看看哪些工作负载能从 FP16 的加速中获益。我们计算了 FP16 平均得分与 FP32 平均得分的比值。结果显示,WaveGlow、Tacotron2、SSD 和 NCF 的获益并不明显。

从基准测试结果看性能亮点
开发团队
-
混合精度加速:FP16 能为 BERT 基础版带来最高 2.04 倍的加速,让相同时间内可以完成两倍的实验 -
出色的多 GPU 扩展性:增加 GPU 虽有少量性能损耗,但在多 GPU 配置下,每个基准测试都接近完美扩展
生产部署
-
工作负载通用性:在 10 个基准测试模型中(从自然语言处理到计算机视觉)均表现出色 -
线性扩展:4x GPU 配置下,BERT 基础版能达到 3.94 倍的扩展,展现出优秀的性价比 -
性价比优化:所有 GPU 都能为生产环境中的 AI 工作负载提供出色的扩展效率
研究机构
-
特定领域优势:在视觉(ResNet50、SSD)、语言(BERT、TransformerXL)和音频(Tacotron2、WaveGlow)模型中均表现顶尖 -
精度灵活性:可根据精度需求选择 FP16(1.70-2.04 倍加速)或 FP32。参考我们的平均加速比,就能知道您的工作负载是否能有效扩展 -
硬件优化:这些基准测试能帮您根据深度学习工作负载需求选择合适的 GPU 架构,优化 AI 基础设施投资的回报率
我们广泛的基准测试分析显示,现代 GPU 在各种深度学习工作负载中表现出色。数据表明,多 GPU 配置具有接近线性的扩展性 ——2-GPU 设置性能最高可达 1.99 倍,4-GPU 系统则能实现 3.94 倍的加速。
FP16 精度在大多数工作负载中能带来出色的加速,尤其是基于 Transformer 的模型(BERT 和 TransformerXL)。在多 GPU 扩展性方面,基于 Transformer 的模型表现出极高的效率,而 WaveGlow、NCF、Tacotron2 和 SSD 等模型的扩展性稍差。
这些见解能为组织设计 AI 基础设施提供宝贵指导,帮助其匹配特定的工作负载需求,无论是用于研究实验、模型开发还是生产部署。
相关贴子
-

NAMD GPU 基准和硬件建议
2023.11.24 -

Pacefish CFD 中 RTX PRO 6000 Blackwell 系列与 RTX 6000 Ada GPU 的基准测试
2025.09.06 -

GPU 加速流体和粒子模拟-使用 Enginsoft 进行 Particleworks 基准测试
2025.01.10 -

GeForce RTX 4090 RELION Cryo EM 基准测试和分析
2023.01.11 -

RELION GPU 3D 分类基准测试-RTX 6000 Ada、RTX 5000 Ada 和…
2024.01.01
注册我们的通讯。
注册主题
有什么问题吗?
联系我们相关贴子
-
 基准
基准GROMACS 基准测试 NVIDIA RTX 4090
2023.01.13 68分钟阅读 -
 基准
基准AMD EPYC™ 平台优化指南——基于 GA2232 G3V2 的 HPL 性能测试
2024.12.27 22分钟阅读 -
 基准
基准GROMACS GPU 基准测试和硬件建议
2023.08.22 51分钟阅读