
博客
算力难题迎刃而解!贵州某大学 AI 集群项目启动,资源利用效率倍增

在生成式 AI、大模型技术飞速发展的今天,高校科研对算力的需求正迎来爆发式增长。
贵州某大学计算机学院作为全校 AI 学科建设的核心阵地,承载着人工智能、大数据分析等重点科研任务。但随着科研数据指数级增长、模型复杂度飙升,原有算力体系逐渐“力不从心”。
联泰集群为这所高校量身打造全栈解决方案,破解算力困局!
项目背景:科研算力告急,旧设备成“绊脚石”
作为全校算力需求最集中的院系,该学院近年面临双重挑战:
算力需求升级:从 TB 级存储、千卡级并行计算,向 PB 级存储、万卡级协同计算跨越,原有设备难以支撑重大科研项目;
资源浪费严重:历年采购的 GPU 服务器型号繁杂、规格不一,分散管理导致“算力孤岛”突出,资源利用率不足 30%。
为此,学院启动 AI 集群建设项目,核心目标是:新增设备部署+新旧设备无缝兼容+统一管理,打造支撑多学科、多用户的一体化算力服务平台。
核心需求:四大维度,构建全场景算力支撑
项目需求聚焦四大核心,精准匹配教学科研双重场景:
1. 异构算力兼容:整合 36 台存量多规格 GPU 服务器 + 新增 5 台 8 卡 GPU(单卡 96GB),实现不同品牌、代际 GPU 统一调度;
2. 存储网络支撑:整合 Ceph、GPFS 存储实现 PB 级数据共享,优化 IB/业务网络,保障低延迟高带宽传输;
3. 多租户管理:支持 200 个师生团队、跨院系租户,实现数据隔离、配额管控,避免资源抢占;
4. 多场景适配:支撑大模型研发、AI 课程实践等场景,支持裸金属、容器等灵活部署模式。
核心痛点:X86+ARM 混合架构,融合与门槛双重难题
项目推进中,两大痛点尤为突出:
1. 技术门槛高:团队长期使用 X86 架构,对新增的 ARM 架构算力节点的技术特性、操作逻辑、性能调优了解不足,运维经验欠缺;
2. 架构兼容顾虑:担忧“X86+ARM”混合架构无法顺畅协同,若出现资源孤岛或调度断层,不仅浪费新增算力,还可能干扰现有科研业务稳定性。
联泰解决方案:全栈赋能,破解算力整合困局
联泰集群深耕高校 AI 算力服务领域多年,依托数十个高校项目落地经验,为学院量身打造“硬件整合+软件赋能+网络优化”全栈解决方案,紧扣“存量盘活、增量提质、统一管控”三大核心目标。
具体实施分为五大关键步骤:
1. 前期调研梳理:专业团队驻场,全面检测存量设备参数与兼容性;多轮访谈明确租户需求、任务优先级,诊断网络瓶颈;
2. 异构算力统一管理:部署 LtAIDC 全栈算力云服务平台,将新旧 GPU 纳入统一算力池,通过系统、驱动、容器层面优化实现兼容,智能调度提升资源利用率;
3. 存储与网络优化:整合 Ceph 与 GPFS 存储,采用“热冷数据分层”策略提速;优化“IB 算力网+业务网+管理网”三网架构,核心链路双备份,保障稳定传输;
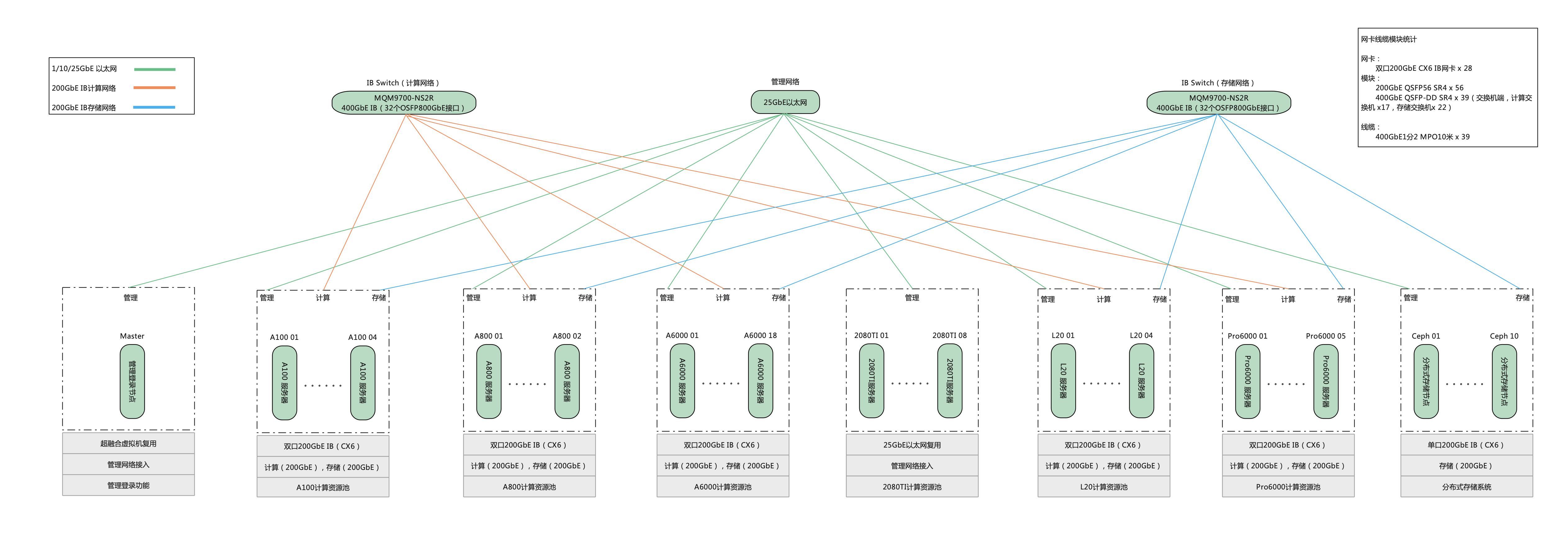
整体方案架构
4. 多租户精细化管控:构建分级租户体系,实现资源配额、数据/网络/资源隔离,配套权限审计与算力计量统计;
5. 部署测试优化:按“先存量后增量、先测试后上线”策略实施,全场景任务测试;提供运维培训,保障长期稳定运行。
项目收益:多维度突破,算力支撑全面升级
项目落地后,为学院带来显著价值提升,核心收益涵盖五大维度:
1. 算力利用率翻倍:破解算力孤岛难题,资源利用率从不足 30% 提升至 75% 以上,新旧设备互补,适配不同复杂度任务;
2. 多租户高效协同:稳定支撑 200 个租户使用,教学与科研协同推进,资源抢占问题彻底解决;
3. 科研效率飙升:GPU 服务器 96GB 大显存搭配平台加速框架,大模型推理速度提升3-5倍,显著缩短科研项目周期;
4. 运维成本大降:可视化运维界面实现资源监控与故障快速排查,运维工作量减少 60% 以上;
5. 夯实学科基础:集群具备良好扩展性,成为 AI 人才培养重要实践平台,助力区域 AI 产业人才输送。
联泰集群始终以“用算力推动生产力”为使命,持续为高校、科研机构提供全栈算力解决方案。如果您的单位也面临算力整合、异构兼容、多场景适配等难题,欢迎随时交流探讨!





相关贴子
-
 技术分享
技术分享【速看】TensorFlow 2.17 发行说明
2024.11.01 20分钟阅读 -
 技术分享
技术分享三种可选的 RAG 模型——SQL、知识库和 API
2025.04.25 42分钟阅读 -
 技术分享
技术分享CryoSparc v5.0.0 重大更新 —— 动态自动遮罩、单 GPU 多任务运行、界面优化及更多新功能
2026.02.12 22分钟阅读